Overview of Spark Architecture & Spark Streaming
Reading Time: 4 minutes

Spark Streaming is designed to provide window-based stream processing and stateful stream processing for any real-time analytics application. Spark applications allows users to do complex processing like running machine learning and graph processing algorithms on real time data streams. This is possible because Spark Streaming uses the Spark Processing Engine under the DStream API to process data.
If implemented the right way, Spark streaming guarantees zero data loss. In this blog, we would be talking about achieving zero data loss in future blog entries. Spark is the execution engine for Spark Streaming, Apache Spark: A look under the Hood gives an overview of Spark Streaming Architecture and How Spark Works.
Let’s dive deeper to see how Spark Streaming accomplishes these things and what goes on under the hood.
Spark Streaming Process
Submitting a Job
When you submit a job on the master. The job starts with the driver on the master and starts the executor on the worker. The executor carries out the crunching of data by executing tasks.
But to run a Spark Streaming job, a spark context is not enough, a Spark Streaming Context must be created as a part of your code. When we start the Streaming Context, using ssc.start(), the driver creates a receiver on one of the Worker nodes and starts an executor process on the worker. Below is a reference code for Spark Streaming NetworkWordCount, it would display word count on a continous stream. This is a long-running Spark Streaming Job.

Receiving the Data
The receiver is responsible for getting data from an external source like Kafka or flume (or any other Spark Streaming Source). The receiver runs as a long-running task within the streaming engine.
Spark Streaming Process
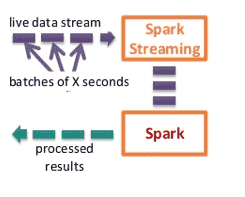
The receiver receives the data and stores it in memory, the default interval is 200ms and this is configurable in Spark Streaming by setting spark.streaming.blockInterval. Similar to the way RDD’s are cached, the blocks are stored in memory using the block manager. It is recommended to not reduce the block interval to less than 50 ms. Since Spark uses the micro-batch approach, it allows users to use the same data processing engine for spark and spark streaming.
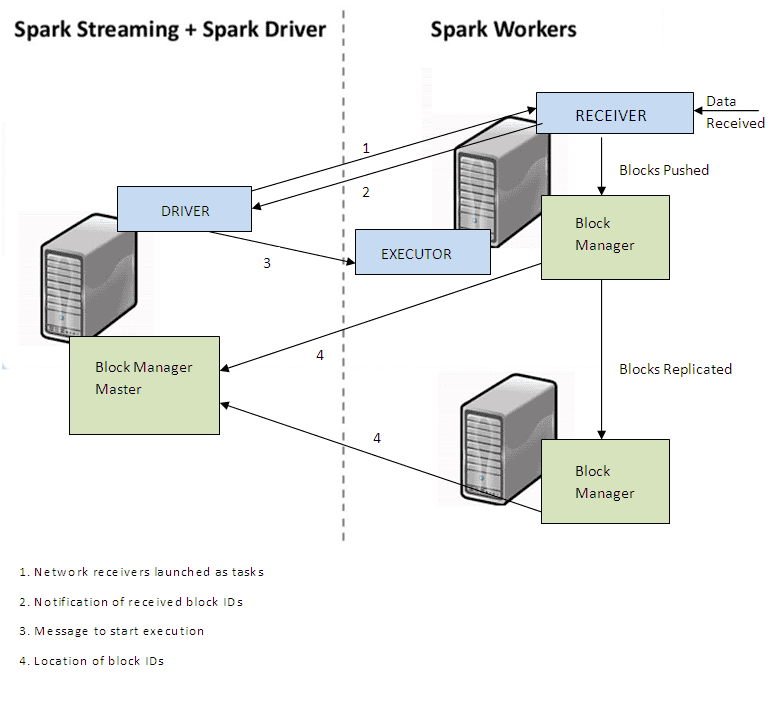
What if the worker goes down before processing the received data?
To avoid data loss in such a situation the data is also replicated on another worker node. This replication is only in memory. I would be talking about fault tolerance in Spark Streaming in my coming blogs.
Execution
Once the blocks are received and stored in memory, each batch is treated as an RDD. The receiver reports the master about the data blocks it receives after every batch interval.
After each batch interval, the Streaming Context asks the executor to process the blocks as RDD’s using the underlying Spark Context. The Spark Core (Spark Processing engine) takes over from this point onward and processes the tasks it has received.
The process goes on, the received chunks are put into blocks by spark streaming and processed by the spark core.
We thank Matei Zaharia, Tathagata Das and other committers for open sourcing Spark under the Apache licence.
About the Author
Arush was a technical team member at Sigmoid. He was involved in multiple projects including building data pipelines and real time processing frameworks.
Featured blogs






Featured blogs