Quantum Computing: Implementing QSVM in IBM Q
Reading Time: 6 minutes

In our previous blog here we have explained the Quantum supremacy experiment. If you are not familiar with Quantum gates, QISKIT and different algorithms, its applications, and resources, I would recommend you to first go through the documentation of IBM-Q and QISKIT, for a detailed context. This blog is for all of you out there who are looking to get up-to-speed quickly on how to use the IBMQ and Qiskit library for running the quantum version of SVM (QSVM) on your computer. I will be talking about the Qiskit library and its uses in the coming sections.
What is QSVM?
Quantum Support Vector Machine (QSVM) is a quantum version of the Support Vector Machine (SVM) algorithm which uses quantum laws to perform calculations. QSVM uses the power of Quantum technology and quantum software to improve the performance of classical SVM algorithms that run on classical machines with CPUs or GPUs.
Quantum Machine Learning takes on two major steps -in the first step classical data is converted to quantum data with computations on the quantum computer and in the second step, the computer converts the quantum result back into the classical format.
Let’s take a look at the different components involved in implementing QSVM?
Kernel trick – used for classifying the dataset into various classes using SVM, which transforms the data to find an optimal boundary between the possible outputs. Data that seems hard to separate in its original space by a simple hyperplane can be separated by applying a non-linear transformation function(known as feature map) in a space known as feature space. The Inner product for each pair of data points in the set is computed to assess the similarity between them and this, in turn, is used to classify the data points in this new feature space (the higher the value of the inner product more similar they are to each other) and this collection of inner products is called the kernel.
Qiskit library – Qiskit is an open-source quantum computing framework developed by IBM. Qiskit can be used to design and manipulate quantum experiments and subsequently run them on simulators on a local computer or real quantum computers on IBM Q Experience. Primarily it uses the Python programming language but it also supports Swift and JavaScript.
Qiskit consists of four foundational elements (Source):
- Qiskit Terra: used to compose the quantum programs at the level of circuits
- Qiskit Aer: accelerates the development via simulators, emulators, and debuggers
- Qiskit Ignis: to address noise and errors
- Qiskit Aqua: used to build algorithms and applications
Installing Qiskit and accessing IBM Q
Here we explain how to code a quantum computer.
For installing Qiskit, to investigating the latest algorithms click here
IBM Q Account offers access to the most advanced cloud-based IBM Q quantum systems and simulators. It helps us to develop, run and monitor jobs/programs by making a stable connection between Qiskit and Quantum computers/devices. Follow these steps to set up your Qiskit environment to send jobs to IBM Q systems.
Qiskit framework consists of three high-level steps:
- Build: design a quantum circuit to solve the problem in hand.
- Execute: run experiments on different backends
- Analyze: calculate summary statistics and visualize the results of the experiments.
To get started with the basics of Qiskit. Here is documentation and video tutorials
Now let us see how the quantum algorithm actually works?
Firstly, superposition is created using the quantum circuit. After encoding and manipulating the information using superposition, we apply interference on the superpositioned states to get the final result.
How QSVM works?
The implementation consists of three basic steps:
- Preprocessing that consists of Scaling, normalization and principal component analysis
- Generation of kernel matrix
- Estimation of the kernel for new set of data points (test data) for QSVM classification.
In the QSVM classification phase, classical SVM is used to generate the separating hyperplane rather than using a quantum circuit and here the quantum computer is used twice. First, the kernel is estimated for all pairs of training data, and the second time the kernel is estimated for a new datum (test data). Least-squares reformulation of the support vector machine is used to change the quadratic programming problem of SVM, into a problem of solving a linear equation system:
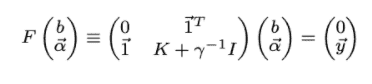
Where,
K is m×m kernel matrix and its elements can be calculated by
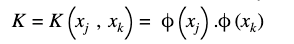
Y is a user-defined value to control the trade-off between training error and SVM objective, y is a vector storing the labels of the training data, So the only unknown parameter in the equation is a vector

After calculating the Kernel matrix on the quantum computer, we can train the Quantum SVM the same way as a classical SVM. Once the parameters of the hyperplane are determined, a new data point x can be classified as
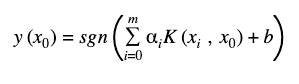
Where,
vector x with i = 1,…,m is the training data,
αi is the with dimension of the parameter vector α
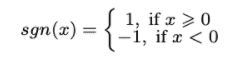
Quantum Algorithm’s parameter
Few important parameters that are specific to the quantum algorithms are:
- feature_dimension: number of features,
- depth: the number of repeated circuits,
- entangler_map: describe the connectivity of qubits [source, target],
- entanglement: generate the qubit connectivity {‘full’- entangles each qubit with all the subsequent ones and ‘linear’ -entangles each qubit with the next}
- feature_map(FeatureMap): feature map module to transform the data to feature space,
- Datapoints: prediction dataset
- quantum_instance (QuantumInstance): quantum backend with all execution settings,
- shots: number of repetitions of each circuit,
- seed_simulator: random seed for simulators,
- seed_transpiler: the random seed for circuit mapper
- QSVM: Quantum SVM method that will run the classification algorithm (binary or multiclass)
QSVM on breast cancer dataset
I have applied SVM on the breast cancer dataset from the Python library Scikit learn both in the classical computer (Conventional SVM) as well as others using a quantum computer (QSVM) simulator in the IBM cloud and its quantum machine learning library Qiskit. The dataset collects information on 31 parameters that characterize a tumor, among which are: average radius, mean perimeter, mean texture, etc. and a total of 569 records.
A snippet of the code applied for QSVM on the simulator (ibmq_qasm_simulator 32 qubits) is shown below
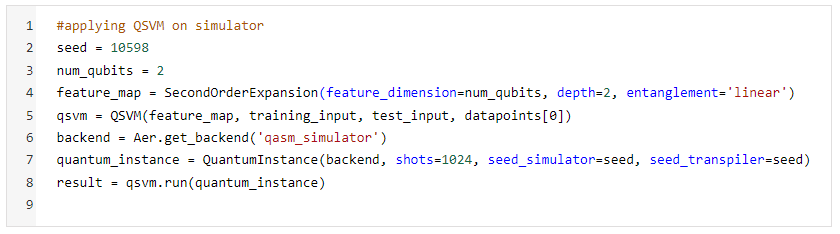
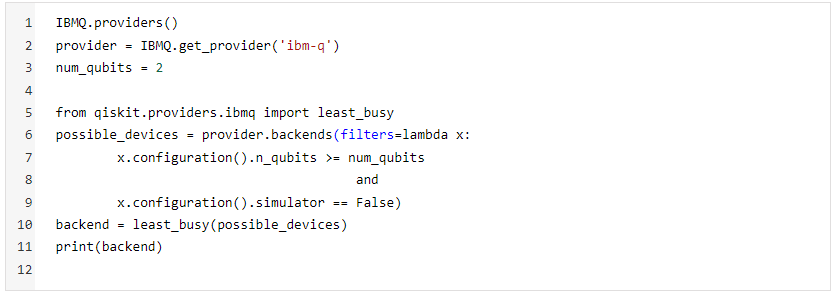
The only difference that we will see while running QSVM on the IBM Q environment (Quantum Computer) is that of the backend. IBM Q has 7 backends for running algorithms on real Quantum devices with different configurations in terms of the number of qubits (highest number of qubits: ibmq_16_melbourne (14 qubits)), their connectivities, error rates, and the type of gate available.
Here is the code for selecting the algorithm on the least busy IBM Q backend
Four simulations were carried out. The first one was classical SVM with all the features, the second was classing SVM with 2 principal components, the third one was a quantum version of SVM (QSVM) on the simulator with 2 principal components and the last one was QSVM on IBM Q again with 2 principal components. This is done to be able to compare the results with each other and of-course the run-time for which the quantum computing and quantum algorithms are taking the limelight.
I will discuss the results of all these once it is ready in my next article in this series! Hope you enjoyed my work and start seeking new challenges within QSVM.
Did you find the article useful? Do you plan to use QSVM in any of your business problems? If yes, share with us how you plan to go about it.
Sources
IBM-Q Documentation – https://quantum-computing.ibm.com/docs/
QISKIT Documentation – https://qiskit.org/documentation/index.html
https://arxiv.org/pdf/1307.0471.pdf
https://arxiv.org/pdf/1804.11326.pdf
https://arxiv.org/pdf/1909.11988.pdf
Authors
Amit Patidar is a Data Scientist at Sigmoid. He works with data and application of Machine Learning algorithms. Currently, he is focusing on Quantum Machine Learning, Recommendation Systems and Big Data architecture.
Assisted by – Bhaskar Ammu. He is a Senior Data Scientist at Sigmoid. He specializes in designing data science solutions for clients, building database architectures, and managing projects and teams.
Featured blogs







Featured blogs